It's no secret that using Nokogiri for parsing is quite slow and the speed is relative to the size of the file you need to parse.
Nokogiri is a DOM based parser where you read the file and build the tree in memory before you parse the contents. This works fine for small files, but when I was trying to load a document that was more than 1GB in size even in a 16GB memory, performance and lockups would happen. Moreover, I had problems where the import became inaccurate because of the failures. Even with the use of Sidekiq, it doesn't address the issue of high memory consumption and lockups of resources (memory, Redis).
Enter SAX parser: an event based parser, which means, it reads the file per line and forms an object when it encounters the closing tag. Together with Sidekiq batch processing, this solves the high memory consumption, resource locking and inaccurate parsing.
ONIX for Books is an XML format for sharing bibliographic data pertaining to both traditional books and eBooks. It is the oldest of the three ONIX standards, and is widely implemented in the book trade in North America, Europe and increasingly in the Asia-Pacific region.
https://en.wikipedia.org/wiki/ONIX_for_Books#:~:text=ONIX for Books is an,in the Asia-Pacific region
The task at hand is to process more than 1M data for books every week, in two split batches of 1+GB and 400+MB ONIX files. With the previous approach of using Nokogiri, I had to babysit this process and monitor the nature of errors as it happens and make adjustments to handle them accordingly. The errors would be around 33-37% each run. The bigger the file, the higher the error rate.
Here's the approach that addressed the issues:
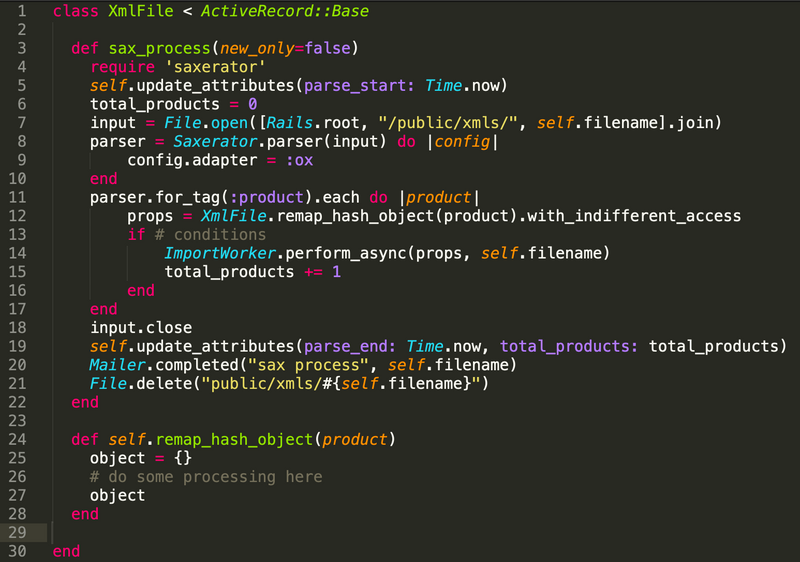
The XmlFile creates the object that holds the attributes for the parsed document. It logs the number of records that were processed and the filename of the document. The records that are imported will refer to this XmlFile object as well to trace back its origin.
class XmlFile < ActiveRecord::Base
def sax_process
require 'saxerator'
self.update_attributes(parse_start: Time.now)
total_products = 0
input = File.open([Rails.root, "/public/xmls/", self.filename].join)
parser = Saxerator.parser(input) do |config|
config.adapter = :ox
end
parser.for_tag(:product).each do |product|
props = XmlFile.remap_hash_object(product).with_indifferent_access
if # conditions
ImportWorker.perform_async(props, self.filename)
total_products += 1
end
end
input.close
self.update_attributes(parse_end: Time.now, total_products: total_products)
Mailer.completed("sax process", self.filename)
File.delete("public/xmls/#{self.filename}")
end
def self.remap_hash_object(product)
props = {}
# do some processing here
props
end
end
Main import processor:
After the parser has formed one object/record, it then passes it to my main import processor and does some processing and branches the work some more to other specific workers.
module MainImporter
def self.import(props, filename)
# Set your main variables
store_ids = [1]
volume_price_model_id = DEFAULT_VOLUME_PRICE_MODEL
props = props.with_indifferent_access
# Do some processing
# Call other worksers after product import: image worker, author worker, category setting worker, etc
end
end
And finally, Sidekiq. The best part of using sidekiq with batch processing, is that you can control if you will have that batch pause or stop. When the batch processing starts, you have an id for the batch that you can check in again and stop it as needed. It can also update you when the batch has completed.
class ImportWorker
include Sidekiq::Worker
sidekiq_options queue: 'low', retry: 6
def perform(data, filename)
MainImporter.import(data, filename)
end
def on_success(status, options)
Mailer.status_update("Import Worker", status).deliver_now
end
def self.process(filename)
batch = Sidekiq::Batch.new
batch.description = "Process ONIX file #{filename}"
batch.on(:success, self)
require 'saxerator'
x = XmlFile.create(filename: filename)
x.update_attributes(parse_start: Time.now)
total_products = 0
input = File.open([Rails.root, "/public/xmls/", x.filename].join)
parser = Saxerator.parser(input) do |config|
config.adapter = :ox
end
batch.jobs do
parser.for_tag(:product).each do |product|
props = XmlFile.remap_hash_object(product).with_indifferent_access
if # conditions are met
perform_async(props, filename)
total_products += 1
end
end
end
input.close
x.update_attributes(parse_end: Time.now, total_products: total_products)
File.delete("public/xmls/#{x.filename}") if Rails.env=="production"
end
end
After this change was implemented, our processing was cut down from hours for the 400+MB file to just under 30 minutes and the bigger file to just under an hour. The accuracy was better and more records were parsed and processed; and the error rate dropped to only 1-2%. With this improvement, we are now faced with a growth of records imported to ~800K records per week depending on the added.